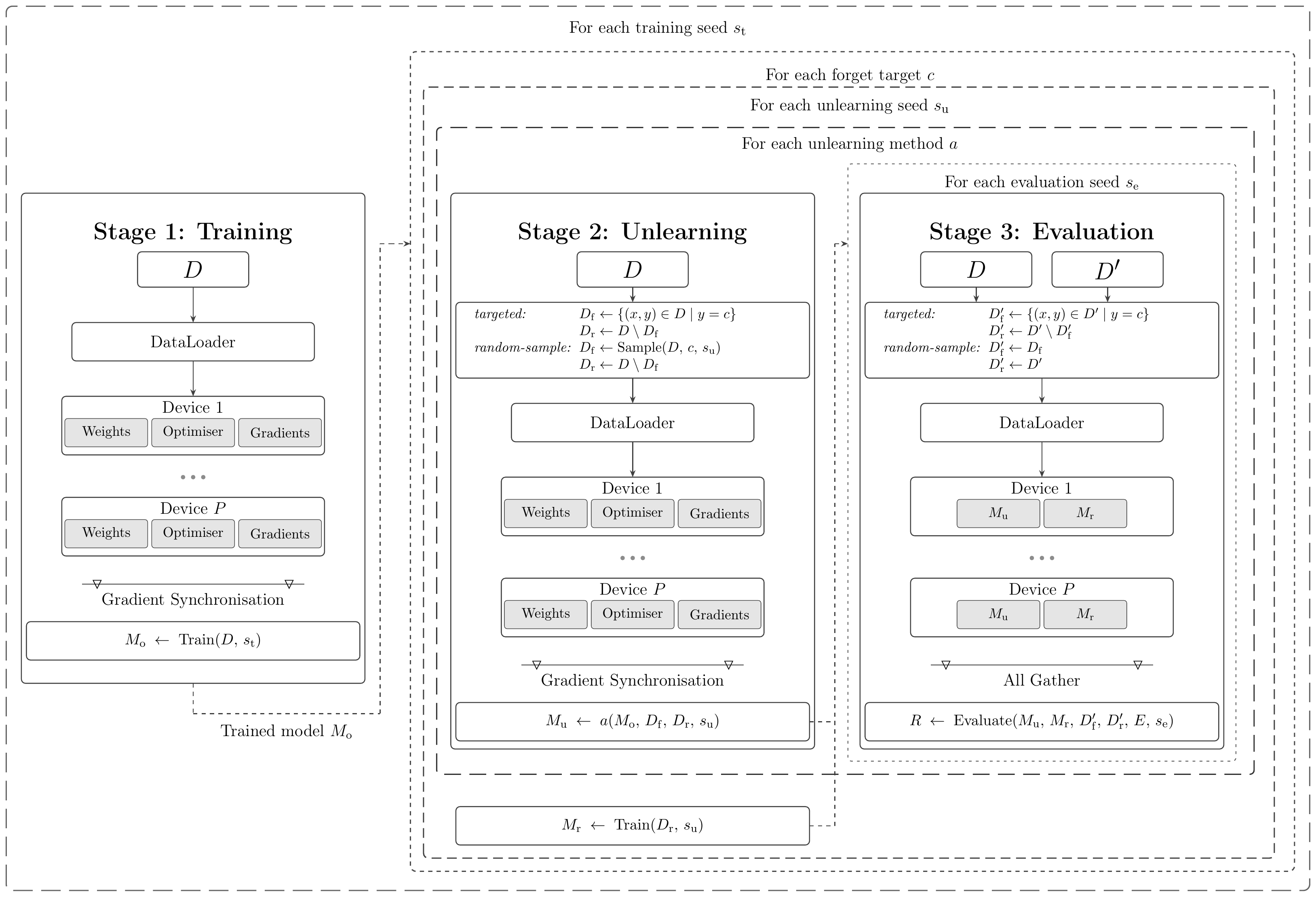
We demonstrate SUPREME on Pins Face Recognition, an image classification benchmark of 17,534 facial images across 105 celebrity identities. Two scenarios are evaluated:
- Full-class unlearning removes all samples for five identities: alex_lawther, bill_gates, danielle_panabaker, hugh_jackman, josh_radnor.
- Random-sample unlearning removes a 0.1% subset of training samples drawn from across all classes.
Both architectures (ResNet18 and ViT) are evaluated across I = 10 training seeds (260–269) on a single NVIDIA L40S GPU to maintain exact numerical parity with the reference implementations. Table 1 reports accuracy differences (ΔAcc) and layer-wise weight distances between Mu and Mr; closer to 0 is better.
Table 1: Accuracy differences and layer-wise distances on Pins Face Recognition
Mean ± std across 10 seeds. Bold marks the best (closest to 0) value in each column within a model–scenario block.
| Model |
Scenario |
Method |
ΔAcc on D'f |
ΔAcc on D'r |
Layer |
| ResNet18 | Full-class | FT | 29.22 ± 5.21 | 2.52 ± 0.11 | 31.52 ± 0.22 |
| BadT | 0.26 ± 0.17 | -2.35 ± 0.27 | 31.72 ± 0.34 |
| UNSIR | 89.44 ± 1.98 | 2.51 ± 0.12 | 32.25 ± 0.34 |
| RL | 0.00 ± 0.00 | 2.58 ± 0.12 | 31.98 ± 0.34 |
| SSD | 1.97 ± 6.22 | -9.14 ± 7.43 | 31.55 ± 0.36 |
| LFSSD | 0.00 ± 0.00 | -3.66 ± 1.53 | 31.56 ± 0.34 |
| Random | FT | 2.78 ± 24.32 | -2.60 ± 15.25 | 37.70 ± 7.91 |
| BadT | -35.00 ± 25.93 | -32.47 ± 29.83 | 41.99 ± 8.78 |
| RL | -48.89 ± 34.03 | -4.59 ± 20.12 | 42.11 ± 8.72 |
| SSD | -75.00 ± 19.47 | -79.97 ± 23.79 | 40.25 ± 9.06 |
| LFSSD | -68.33 ± 15.28 | -58.61 ± 19.20 | 40.82 ± 8.72 |
| ViT | Full-class | FT | 0.03 ± 0.06 | -22.66 ± 23.47 | 105.29 ± 1.31 |
| BadT | 17.90 ± 5.18 | -0.88 ± 0.10 | 33.97 ± 0.12 |
| UNSIR | 35.52 ± 4.92 | -0.31 ± 0.13 | 39.38 ± 0.18 |
| RL | 0.00 ± 0.00 | 0.20 ± 0.05 | 36.92 ± 0.18 |
| SSD | 0.00 ± 0.00 | -2.40 ± 0.99 | 63.38 ± 2.58 |
| LFSSD | 0.00 ± 0.00 | -3.88 ± 2.11 | 86.77 ± 6.07 |
| Random | FT | 8.33 ± 5.40 | 1.42 ± 0.12 | 60.40 ± 0.19 |
| BadT | -8.33 ± 7.97 | 0.21 ± 0.52 | 32.76 ± 0.18 |
| RL | -76.67 ± 11.94 | 1.33 ± 0.12 | 35.71 ± 0.20 |
| SSD | -55.00 ± 37.99 | -54.09 ± 45.60 | 171.80 ± 84.31 |
| LFSSD | -89.44 ± 6.11 | -90.70 ± 6.59 | 231.91 ± 15.22 |
UNSIR is excluded from the random scenario by design. Full-class values average over 5 forget classes; random uses a 0.1% forget set. The large standard deviations in the random-sample row underline the paper's main practical point: single-seed image unlearning results can misrepresent a method's behaviour, and multi-seed evaluation is required for a fair comparison.